Cursos, treinamentos e consultoria em cabeamento estruturado, Fluke Networks CCTT DSX-5000 Versiv DTX-1800, infraestrutura física de data centers, redes em fibra óptica
Em uma iniciativa enriquecedora, Marcelo Barboza, uma autoridade em infraestrutura física de TI, com reconhecimento internacional através de títulos como RCDD, DCDC pela BICSI e ATS pelo Uptime Institute, aceitou o convite da GROZ para uma visita técnica ao data center da Univox. Esta parceria entre a Clarity Treinamentos, empresa de Marcelo, e a GROZ, destacou a importância da colaboração entre especialistas para aprimorar e divulgar conhecimentos sobre as infraestruturas que sustentam o universo digital. A Univox, com sua extensa rede de mais de 1300 quilômetros de cabos de fibra óptica, serve como um pilar para a conectividade na região sul e sudoeste de Minas Gerais, e a visita de Marcelo lançou luz sobre os bastidores dessa operação monumental.
Aprofundando-se na Origem da Internet
A jornada de descoberta de Marcelo começou com uma questão fundamental: como o sinal da internet é gerado e distribuído até chegar aos usuários finais? Ao adentrar o data center da Univox, ele desvendou a complexidade da infraestrutura necessária para essa façanha. A visita, enriquecida pela parceria com a GROZ, permitiu a Marcelo uma análise detalhada dos sistemas e processos que compõem o backbone da conectividade na era digital.
Dentro do Data Center: Uma Visão Técnica
Marcelo explorou com precisão técnica os componentes críticos do data center. Ele destacou a importância dos racks trancados e monitorados por câmeras de CFTV, uma medida de segurança essencial para proteger os equipamentos de acesso não autorizado. A presença de redes CDN de gigantes da internet, como Google, Facebook e Netflix, foi um ponto de interesse particular, demonstrando a capacidade da Univox de fornecer acesso rápido a conteúdos populares através de equipamentos dedicados que funcionam como caches locais.
Resiliência e Eficiência Energética
A visita proporcionou insights sobre a resiliência do data center contra interrupções de energia. Marcelo examinou os sistemas UPS e geradores a diesel, destacando a engenharia por trás da continuidade ininterrupta do serviço. A eficiência energética também foi um tema explorado, com Marcelo detalhando o uso de sistemas de ar-condicionado de precisão para gerenciamento térmico, essenciais para manter a operação dos equipamentos dentro de parâmetros ideais e evitar o superaquecimento.
A Importância do Monitoramento
A operação 24/7 do NOC (Network Operations Center) foi outro aspecto técnico abordado por Marcelo. Ele descreveu como o NOC serve como os olhos e ouvidos do data center, utilizando telões e estações de trabalho individuais para monitorar constantemente a saúde da rede, a integridade dos sistemas e responder prontamente a qualquer incidente.
Conclusão: A Visão de um Especialista
A visita técnica de Marcelo Barboza ao data center da Univox, a convite da GROZ e em parceria com a Clarity Treinamentos, ofereceu uma visão abrangente e detalhada do que é necessário para manter a infraestrutura digital do mundo em funcionamento. Através desta colaboração, Marcelo conseguiu não apenas explorar os aspectos técnicos do data center, mas também destacar a importância da educação e da parceria entre especialistas para avançar no campo da infraestrutura de TI. Este relato detalhado serve como uma fonte de inspiração e conhecimento para profissionais da área e entusiastas da tecnologia, reforçando a importância de uma infraestrutura robusta e confiável para o futuro digital. Assista a íntegra do vídeo, disponível logo a seguir.
Os data centers são verdadeiramente o coração pulsante da nossa era digital. Essas instalações complexas são responsáveis por armazenar, processar e proteger uma imensa quantidade de dados, essenciais para o funcionamento de empresas e serviços ao redor do mundo. Este guia tem como objetivo desmistificar algumas das práticas de alta prioridade, fundamentais para a eficiência e sustentabilidade dos data centers. Este artigo visa fornecer insights claros e compreensíveis sobre como otimizar as operações desses ambientes vitais.
Neste artigo, abordaremos uma série de recomendações cruciais para a otimização e eficiência dos data centers, cobrindo temas essenciais que vão desde a formação de um Grupo de Aprovação Multidisciplinar – essencial para uma tomada de decisão abrangente e informada -, até o conhecimento profundo de seu data center através de auditorias físicas e lógicas. Exploraremos também as melhores práticas para o descomissionamento e remoção de equipamentos inativos, visando não apenas a liberação de espaço valioso, mas também a redução de custos operacionais. A consolidação de serviços será destacada como uma estratégia poderosa para otimizar recursos e eficiência. Além disso, delinear-se-ão estratégias eficientes de gerenciamento térmico, fundamentais para manter a integridade e o desempenho dos equipamentos. Por fim, discutiremos como o aproveitamento do free cooling pode significar um avanço significativo na redução do consumo energético, alinhando-se às práticas de sustentabilidade e eficiência energética. Essas recomendações são projetadas para equipar os gestores de data centers com as ferramentas necessárias para operar de maneira mais eficiente, sustentável e econômica, garantindo a resiliência e a continuidade dos serviços críticos.
É imperativo destacar que todas as práticas recomendadas discutidas neste artigo são consideradas de alta prioridade e aplicáveis universalmente a todos os data centers, sejam eles novos ou em processo de expansão, abrangendo integralmente todos os seus equipamentos de TI, mecânicos e elétricos. Essa abordagem é endossada pela mais recente edição (2023) das “Diretrizes de Melhores Práticas para o Código de Conduta da UE sobre Eficiência Energética em Data Centers” (Best Practice Guidelines for the EU Code of Conduct on Data Centre Energy Efficiency), documento que serve como um marco regulatório e orientativo para a operação e design de data centers em busca de otimização energética e sustentabilidade. A aderência a estas diretrizes não apenas reforça o compromisso com a eficiência energética, mas também assegura que as operações dos data centers estejam alinhadas com as práticas mais avançadas e responsáveis do setor, garantindo uma infraestrutura tecnológica mais verde, eficiente e sustentável para o futuro.
Grupo de Aprovação Multidisciplinar
O conceito de um Grupo de Aprovação Multidisciplinar em data centers é fundamental para garantir que as decisões tomadas reflitam uma compreensão abrangente e integrada de todas as áreas impactadas pela operação dessas instalações críticas. Este grupo é essencialmente uma equipe formada por representantes de várias disciplinas dentro da organização, cada um trazendo sua expertise específica para o processo de tomada de decisão. Vamos explorar mais a fundo a importância, composição e funções desse grupo.
A Importância de um Grupo de Aprovação Multidisciplinar
A complexidade de um data center é tal que decisões tomadas em isolamento, sem considerar as interdependências entre diferentes áreas, podem levar a resultados subótimos ou até prejudiciais. Por exemplo, uma decisão sobre a aquisição de novo hardware de TI pode ter implicações significativas não apenas para o orçamento, mas também para a capacidade de refrigeração necessária, o consumo de energia, e a gestão do espaço físico. A formação de um Grupo de Aprovação Multidisciplinar assegura que todas essas considerações sejam avaliadas de forma holística.
Composição do Grupo
A composição desse grupo é deliberadamente diversificada para abranger todas as áreas-chave envolvidas na gestão de um data center. Tipicamente, inclui:
Gerência Sênior: Fornece uma visão estratégica e assegura que as decisões estejam alinhadas com os objetivos de negócios da organização.
TI (Tecnologia da Informação): Representa as necessidades e requisitos do núcleo tecnológico, incluindo hardware, software e rede.
Engenharia M&E (Mecânica e Elétrica): Especialistas em infraestrutura física, focados em alimentação elétrica, climatização e outras necessidades físicas do data center.
Software/Aplicações: Foca nas necessidades específicas das aplicações que serão hospedadas no data center, garantindo que o ambiente seja capaz de suportá-las adequadamente.
Aquisições: Responsável por avaliar fornecedores, negociar contratos e adquirir equipamentos e serviços dentro dos parâmetros de custo e qualidade.
Funções e Benefícios
O Grupo de Aprovação Multidisciplinar tem várias funções essenciais, incluindo:
Avaliação Holística: Garantir que todas as decisões sejam tomadas com uma compreensão completa de seus impactos em todas as áreas do data center.
Governança e Conformidade: Assegurar que as decisões estejam em conformidade com as normas e padrões aplicáveis, como ANSI/TIA-942, BICSI-002, e ISO/IEC 22237.
Otimização de Recursos: Promover a utilização eficiente dos recursos, identificando oportunidades para melhorar a eficiência energética, a gestão do espaço e a capacidade de refrigeração.
Inovação e Melhoria Contínua: Encorajar a adoção de novas tecnologias e práticas que possam melhorar a operação e sustentabilidade do data center.
A implementação de um Grupo de Aprovação Multidisciplinar é, portanto, um passo crítico para qualquer organização que busca otimizar suas operações de data center de maneira sustentável e eficiente, garantindo que todas as decisões sejam informadas, estratégicas e alinhadas com os objetivos globais da empresa.
Conhecendo Seu Data Center: Auditoria Física e Lógica
Para otimizar um data center de maneira eficaz, é fundamental ter um conhecimento aprofundado sobre os ativos e recursos disponíveis. A auditoria, tanto do estado físico quanto lógico dos componentes do data center, emerge como o passo inicial e crucial nesse processo. Essa abordagem meticulosa permite uma compreensão detalhada dos equipamentos em operação e dos serviços que estão sendo fornecidos.
Implementação de Ferramentas de Gestão Baseadas em ITIL
A adoção de um Banco de Dados de Gerenciamento de Configuração (CMDB, na sigla em inglês) e de um Catálogo de Serviços, ambos conceitos fundamentais da Information Technology Infrastructure Library (ITIL), é altamente recomendada. Essas ferramentas são essenciais para manter um registro organizado e atualizado dos ativos de TI e dos serviços oferecidos pelo data center.
Banco de Dados de Gerenciamento de Configuração (CMDB)
O CMDB é uma base de dados que armazena informações sobre os elementos de configuração (ECs) importantes dentro da infraestrutura de TI. No contexto de um data center, isso inclui:
Detalhes sobre hardware, como servidores, switches, e dispositivos de armazenamento.
Informações sobre software, incluindo sistemas operacionais, aplicativos e licenças.
Configurações de rede e relações entre os diferentes componentes de TI.
Ao manter essas informações atualizadas, o CMDB oferece uma visão holística do ambiente de TI, facilitando a identificação de dependências e o impacto de mudanças e falhas potenciais.
Catálogo de Serviços
O Catálogo de Serviços, por sua vez, é um documento ou sistema que lista todos os serviços de TI disponíveis, incluindo descrições detalhadas, usuários ou departamentos destinatários, e informações sobre como solicitar cada serviço. Ele serve como uma ponte entre a TI e seus usuários, esclarecendo o que está disponível e como acessar os serviços necessários.
Benefícios da Auditoria e da Implementação de ITIL
Visibilidade Aumentada: Ter visibilidade completa sobre os ativos físicos e lógicos permite que a equipe de TI gerencie melhor os recursos, antecipe necessidades de manutenção e planeje upgrades de forma proativa.
Otimização de Recursos: Identificar equipamentos subutilizados ou obsoletos e serviços redundantes pode levar a uma otimização significativa, reduzindo custos e melhorando a eficiência operacional.
Melhoria Contínua: Com um registro detalhado e organizado, torna-se mais fácil identificar áreas para melhorias contínuas, seja em termos de desempenho, segurança ou conformidade.
Gestão de Mudanças: Facilita a gestão de mudanças ao proporcionar um entendimento claro do ambiente atual e como as alterações propostas afetarão o sistema como um todo.
Em resumo, a realização de uma auditoria abrangente, tanto física quanto lógica, combinada com a implementação de práticas inspiradas na ITIL, como o CMDB e o Catálogo de Serviços, coloca o data center em uma posição de força para otimização e crescimento sustentável. Essa estratégia não apenas simplifica a gestão de recursos, mas também pavimenta o caminho para melhorias contínuas e uma operação mais eficiente
Descomissionamento e Remoção de Equipamentos Inativos
O descomissionamento e a remoção de equipamentos inativos constituem uma etapa crucial na gestão eficiente de um data center. Equipamentos que não estão mais em uso ou que não suportam serviços ativos, incluindo plataformas de teste e desenvolvimento que se tornaram obsoletas, representam um desperdício significativo de espaço e recursos valiosos. Essa prática não só é fundamental para otimizar o uso do espaço físico dentro do data center, mas também desempenha um papel importante na redução do consumo de energia, alinhando-se assim aos objetivos de sustentabilidade.
Processo de Descomissionamento e Remoção
Identificação de Equipamentos Inativos: O primeiro passo envolve a identificação cuidadosa de todos os equipamentos inativos ou obsoletos. Isso pode ser realizado através de auditorias regulares e revisões do inventário, utilizando ferramentas de gestão de ativos e dados de monitoramento para identificar hardware que não está mais servindo a propósitos produtivos.
Avaliação e Planejamento: Após a identificação, é essencial avaliar o impacto potencial do descomissionamento de cada peça de equipamento. Isso inclui verificar dependências, avaliar a possibilidade de reutilização em outros contextos dentro do data center ou em outras instalações, e planejar a remoção de forma que minimize a interrupção das operações.
Execução Segura e Responsável: O descomissionamento e a remoção devem ser executados de maneira segura e responsável. Isso envolve garantir que todos os dados contidos nos dispositivos sejam adequadamente apagados, seguindo padrões de segurança para a eliminação de dados. Além disso, é importante considerar as melhores práticas ambientais para o descarte ou reciclagem de hardware, seguindo regulamentações locais e internacionais pertinentes.
Benefícios do Descomissionamento e Remoção
Otimização do Espaço: A remoção de equipamentos inativos libera espaço valioso dentro do data center, que pode ser melhor utilizado para acomodar hardware mais moderno e eficiente, ou para outras necessidades operacionais.
Redução do Consumo de Energia: Equipamentos obsoletos ou inativos muitas vezes continuam consumindo energia, mesmo sem suportar serviços ativos. Sua remoção contribui para a redução do consumo de energia geral do data center, o que não apenas resulta em economia de custos, mas também minimiza a pegada de carbono da instalação.
Contribuição para a Sustentabilidade: Além de reduzir o consumo de energia, o processo de descomissionamento e remoção de equipamentos inativos alinha-se com práticas de sustentabilidade, ao promover o uso eficiente de recursos e incentivando a reciclagem e o descarte responsável de hardware.
Em suma, o descomissionamento e a remoção de equipamentos inativos são etapas essenciais para a manutenção da eficiência operacional e sustentabilidade de um data center. Esse processo não apenas maximiza o uso do espaço e recursos disponíveis, mas também reforça o compromisso com práticas ambientalmente responsáveis. Ao adotar uma abordagem sistemática e responsável para o descomissionamento, os data centers podem melhorar significativamente seu desempenho operacional e contribuir para um futuro mais sustentável.
Otimizando com a Consolidação de Serviços
A consolidação dos serviços existentes em um data center é um processo estratégico que visa otimizar o uso de recursos de hardware, que frequentemente são subutilizados, operando bem abaixo de sua capacidade total. Esta subutilização não só representa um desperdício de recursos valiosos, mas também contribui para custos operacionais e de energia desnecessariamente altos. Através da implementação de tecnologias de compartilhamento de recursos, como a virtualização, é possível realizar uma consolidação eficaz dos serviços, melhorando a utilização dos recursos físicos e, consequentemente, otimizando o desempenho geral do data center.
Implementação de Tecnologias de Compartilhamento de Recursos
Virtualização: A virtualização é a espinha dorsal da consolidação de serviços. Ela permite que múltiplas instâncias de sistemas operacionais e aplicações sejam executadas em um único servidor físico, compartilhando seus recursos. Isso não só aumenta a eficiência na utilização do hardware, mas também facilita a gestão e a escalabilidade dos serviços.
Containers: Os containers oferecem uma abordagem mais leve à virtualização, permitindo que aplicações sejam empacotadas com todas as suas dependências, o que facilita a movimentação entre diferentes ambientes de computação. Isso otimiza ainda mais o uso dos recursos de hardware, ao mesmo tempo em que proporciona uma gestão simplificada dos serviços.
Benefícios da Consolidação de Serviços
Otimização do Uso do Hardware: Ao consolidar serviços que utilizam apenas uma fração de sua capacidade de hardware, maximiza-se a utilização desses recursos. Isso significa que menos hardware é necessário para suportar a mesma quantidade de trabalho, o que pode levar a uma redução significativa no investimento em novos equipamentos.
Economia nos Custos Operacionais e de Energia: A consolidação de serviços reduz o número de servidores físicos necessários, o que, por sua vez, diminui o consumo de energia e os custos de refrigeração. Além disso, com menos hardware para gerenciar, os custos operacionais associados à manutenção e ao suporte técnico também são reduzidos.
Melhoria na Eficiência Operacional: A gestão de um ambiente consolidado é inerentemente mais eficiente. Com menos servidores físicos para monitorar e manter, as equipes de TI podem focar em melhorias operacionais e inovações, ao invés de se ocuparem com a manutenção de uma infraestrutura inchada e subutilizada.
Contribuição para a Sustentabilidade: A consolidação de serviços contribui diretamente para as iniciativas de sustentabilidade do data center, reduzindo o consumo de energia e a pegada de carbono. Menos hardware e um uso mais eficiente da energia alinham-se com objetivos ambientais mais amplos, reforçando o compromisso do data center com práticas sustentáveis.
Em resumo, a consolidação dos serviços existentes por meio de tecnologias de compartilhamento de recursos como a virtualização é uma estratégia essencial para otimizar o uso do hardware em data centers. Esta abordagem não só melhora significativamente a utilização dos recursos físicos, mas também oferece economias consideráveis nos custos operacionais e de energia, ao mesmo tempo em que contribui para a sustentabilidade e eficiência operacional. Implementar uma estratégia de consolidação bem planejada é, portanto, fundamental para qualquer data center que busca otimizar suas operações e seu impacto ambiental.
Estratégias Eficientes de Gerenciamento Térmico
O gerenciamento térmico eficiente é um pilar fundamental na operação de data centers, não apenas para garantir a confiabilidade e o desempenho ótimo dos dispositivos de TI, mas também para otimizar o consumo de energia e reduzir os custos operacionais. Uma das estratégias mais eficazes para alcançar uma gestão térmica adequada é o design de corredores quentes e frios, complementado pela contenção de ar. Esta abordagem não só melhora significativamente a eficiência do resfriamento, mas também se adapta de forma flexível às variações de carga térmica dos dispositivos de TI.
Design de Corredores Quentes e Frios
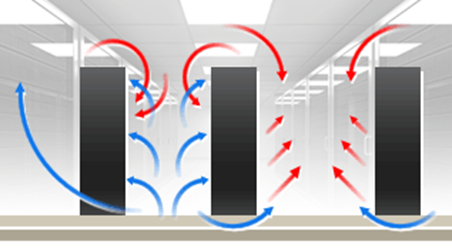
O design de corredores quentes e frios envolve a organização física dos racks de servidores de maneira que os exaustores de todos os equipamentos estejam voltados para o mesmo lado (corredor quente), enquanto as entradas de ar estão voltadas para o lado oposto (corredor frio). Essa configuração cria zonas distintas de ar frio e quente dentro do data center, permitindo uma separação clara entre o ar que está sendo resfriado para ser usado pelos equipamentos e o ar que já foi aquecido por eles.
Benefícios do Design de Corredores Quentes e Frios
Eficiência no Resfriamento: Ao separar claramente o ar frio do ar quente, evita-se a mistura de ar quente com ar frio, aumentando a eficiência do sistema de resfriamento.
Redução de Custos de Energia: A eficiência aprimorada na refrigeração resulta em menor consumo de energia, o que se traduz em economias significativas nos custos de energia.
Maior Confiabilidade dos Equipamentos: A manutenção de temperaturas operacionais ótimas aumenta a confiabilidade e a vida útil dos dispositivos de TI.
Contenção de Ar
A contenção de ar é uma prática que aprimora ainda mais a estratégia de corredores quentes e frios. Pode ser implementada de duas formas principais: contenção de corredor frio e contenção de corredor quente.
Contenção de Corredor Frio
Na contenção de corredor frio, os corredores onde o ar frio é introduzido são fechados, geralmente com portas nas extremidades e coberturas no topo. Isso assegura que o ar frio seja direcionado exclusivamente para a entrada dos equipamentos, aumentando a eficiência do resfriamento.
Contenção de Corredor Quente
Similarmente, na contenção de corredor quente, os corredores por onde o ar quente é exaurido são fechados. Isso facilita a remoção eficiente do ar quente do ambiente, permitindo que o sistema de resfriamento opere com maior eficiência.
Adaptação às Variações de Carga Térmica
Um dos aspectos mais valiosos da implementação de corredores quentes e frios, juntamente com a contenção de ar, é a capacidade de adaptar-se rapidamente às variações de carga térmica dos dispositivos de TI. À medida que a demanda de processamento varia, a geração de calor pelos equipamentos também muda. A estratégia de corredores quentes e frios, especialmente quando combinada com sistemas de contenção de ar, permite ajustes mais rápidos e precisos nos sistemas de climatização, garantindo que as condições ideais de operação sejam mantidas constantemente.
Em conclusão, a implementação cuidadosa do design de corredores quentes e frios, complementada pela contenção de ar, representa uma estratégia sofisticada e altamente eficaz para o gerenciamento térmico em data centers. Esta abordagem não só assegura uma operação eficiente e confiável dos dispositivos de TI, mas também promove uma significativa economia de energia, alinhando-se com os objetivos de sustentabilidade e eficiência operacional dos data centers modernos.
Aproveitando o Free Cooling
O free cooling representa uma abordagem inovadora e sustentável para o resfriamento de data centers, capitalizando sobre as condições ambientais externas para reduzir a dependência de sistemas de refrigeração mecânica, como ar-condicionado e chillers. Essa técnica não só promove uma operação mais verde e eficiente em termos energéticos, mas também pode resultar em economias substanciais de custos operacionais a longo prazo. No entanto, a implementação efetiva do free cooling em data centers, especialmente naqueles situados em zonas tropicais, requer uma análise cuidadosa e uma abordagem adaptada às condições climáticas específicas dessas regiões.
Desafios do Free Cooling em Zonas Tropicais
Zonas tropicais apresentam desafios únicos para a implementação de free cooling devido às suas condições climáticas características, que incluem temperaturas elevadas durante todo o ano e alta umidade. Esses fatores podem limitar a eficácia do free cooling, uma vez que o ar externo pode não estar suficientemente frio para ser usado diretamente no resfriamento do ambiente interno, ou pode requerer tratamento adicional para reduzir sua umidade a níveis aceitáveis para a operação segura dos equipamentos de TI.
Estratégias para Maximizar a Eficiência do Free Cooling em Zonas Tropicais
1. Análise Climática Detalhada: Antes de implementar o free cooling, é crucial realizar uma análise climática detalhada da região onde o data center está localizado. Isso inclui não apenas a temperatura média, mas também a variação diurna e sazonal, bem como a umidade relativa. Essa análise ajudará a identificar períodos do ano ou do dia em que o free cooling seria mais eficaz.
2. Tecnologias de Tratamento do Ar: Para lidar com a alta umidade, podem ser utilizadas tecnologias de tratamento do ar, como desumidificadores ou sistemas de resfriamento indireto, que permitem o uso do free cooling sem introduzir umidade excessiva no ambiente interno. Essas tecnologias podem ser combinadas com sistemas de controle inteligente para otimizar a operação com base nas condições ambientais em tempo real.
3. Sistemas Híbridos de Resfriamento: Em zonas tropicais, o free cooling pode ser mais eficaz quando usado como parte de um sistema híbrido, complementando, em vez de substituir completamente, o resfriamento mecânico. Por exemplo, durante as horas mais frias do dia ou em estações mais amenas, o free cooling pode ser utilizado para reduzir a carga sobre os sistemas de refrigeração mecânica, maximizando a eficiência energética.
4. Isolamento e Vedação Eficientes: Para maximizar os benefícios do free cooling, é essencial garantir que o data center esteja bem isolado e vedado, minimizando a troca de calor indesejada com o ambiente externo. Isso inclui a implementação de barreiras de vapor e isolamento térmico eficaz nas paredes, tetos e pisos.
5. Adaptação Arquitetônica: A concepção arquitetônica do data center pode ser adaptada para facilitar o free cooling, como a orientação do edifício para aproveitar os ventos predominantes ou a inclusão de elementos arquitetônicos que promovam a ventilação natural.
A implementação de free cooling em data centers localizados em zonas tropicais demanda uma abordagem cuidadosa e personalizada, considerando as peculiaridades climáticas da região. Apesar dos desafios, com planejamento adequado e a utilização de tecnologias adaptadas, é possível maximizar a eficiência do free cooling, reduzindo significativamente a dependência de refrigeração mecânica, os custos operacionais e o impacto ambiental. Investigar a viabilidade do free cooling, especialmente em novas construções ou atualizações de sistemas existentes, é um passo fundamental para data centers que buscam operações mais sustentáveis e eficientes.
Conclusão: Rumo a Data Centers Mais Eficientes e Sustentáveis
As práticas abordadas neste guia são cruciais para a operação eficiente e sustentável de um data center. A adoção dessas recomendações não apenas melhora o desempenho operacional, mas também contribui significativamente para a redução do impacto ambiental. Encorajamos todos os profissionais de data center a integrar essas práticas em suas operações, buscando continuamente melhorias para manter seus ambientes de TI resilientes e eficientes.
Este artigo serve como um ponto de partida essencial para aqueles que estão começando a explorar o fascinante mundo dos data centers, oferecendo uma base sólida de práticas recomendadas que garantem a eficiência e a sustentabilidade dessas infraestruturas indispensáveis.
Na era digital contemporânea, os data centers emergem como os pilares fundamentais que sustentam o colossal volume de processamento de dados e serviços de infraestrutura de TI que impulsionam negócios e comunicações globais. A eficiência energética dessas instalações críticas transcende a mera redução de custos operacionais, posicionando-se como um componente vital para a sustentabilidade ambiental e a responsabilidade corporativa. Este artigo é um compêndio destinado a orientar gestores de TI, engenheiros de infraestrutura e técnicos sobre metodologias para a implementação de novos equipamentos de TI em data centers, com ênfase na maximização da eficiência energética e na promoção de práticas sustentáveis.
A Eficiência Energética como Pilar de Sustentabilidade em Data Centers
A Crucialidade da Eficiência Energética
A eficiência energética em data centers é uma questão multifacetada que abrange a economia de custos operacionais, a minimização do impacto ambiental e a otimização do desempenho do equipamento. A demanda por serviços de data center está em uma trajetória ascendente, impulsionada pela proliferação de dispositivos conectados, a expansão do armazenamento em nuvem e o crescimento exponencial do big data. A eficiência energética torna-se, portanto, um elemento crítico para a sustentabilidade, permitindo que os data centers atendam a essa demanda crescente de maneira responsável e econômica.
Normas e Padrões que Moldam a Eficiência Energética
A aderência a normas e padrões internacionais é imperativa para assegurar a eficiência energética em data centers. Normas como as da American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE), especificamente as diretrizes ASHRAE Class A2, fornecem um conjunto de parâmetros para a operação e design de data centers eficientes. Da mesma forma, a ISO/IEC e a legislação da União Europeia estabelecem critérios rigorosos para a eficiência energética de equipamentos de TI, promovendo práticas que reduzem o consumo de energia e as emissões de gases de efeito estufa. Confira nosso artigo sobre normas para data centers.
Estratégias para a Seleção de Equipamentos de TI Eficientes
Priorizando a Eficiência Energética na Escolha do Hardware
A seleção de novos equipamentos de TI deve ser guiada por uma avaliação criteriosa da eficiência energética. A performance energética de um dispositivo deve ser um fator decisivo no processo de aquisição, influenciando a escolha de hardware de TI. Métricas como as fornecidas pelo Standard Performance Evaluation Corporation (SPEC) através de ferramentas como SERT (System Energy Efficiency Ratio Test) e SPECPower servem como benchmarks confiáveis para avaliar e comparar a eficiência energética de dispositivos de hardware.
Considerações sobre Temperatura e Umidade na Operação de Equipamentos
Os equipamentos de TI devem ser selecionados com base em sua capacidade de operar eficientemente em uma gama de temperaturas e umidades, conforme estabelecido pelas diretrizes ambientais da ASHRAE. A escolha de dispositivos que funcionam dentro dos parâmetros da Classe A2 da ASHRAE garante que eles operem de maneira eficiente sob uma variedade de condições ambientais, mantendo a integridade da garantia e prolongando a vida útil do equipamento.
Avaliando o Consumo de Energia em Função da Temperatura
O consumo de energia dos equipamentos de TI pode variar significativamente com a temperatura do ambiente em que estão operando. Ao selecionar novos dispositivos, é crucial exigir dos fornecedores informações detalhadas sobre o consumo total de energia em uma gama de temperaturas, abrangendo toda a faixa de temperatura admissível para o equipamento. Isso é particularmente importante para data centers que operam em ambientes com temperaturas variáveis, pois permite uma avaliação precisa do impacto térmico sobre o consumo de energia.
Operação Eficiente dos Equipamentos de TI
O Papel do Gerenciamento de Energia na Implantação de Equipamentos
A ativação de recursos de gerenciamento de energia é um passo crítico durante a implantação de novos equipamentos. Configurações de BIOS, sistemas operacionais e drivers devem ser otimizados para promover a eficiência energética. Essas configurações ajudam a reduzir o consumo de energia desnecessário e a melhorar a eficiência operacional dos dispositivos recém-instalados.
Virtualização: Otimizando o Uso de Hardware
A virtualização é uma técnica que permite a consolidação de múltiplos serviços em uma única plataforma de hardware, otimizando o uso de recursos e reduzindo a necessidade de equipamentos dedicados. A implementação de uma política que exige a aprovação de negócios sênior para a aquisição de hardware dedicado incentiva a consideração da virtualização como uma alternativa viável, promovendo a eficiência energética e a utilização de recursos.
Melhorando a Eficiência do Fluxo de Ar em Data Centers
Implementando o Conceito de Corredores Quentes e Frios
O design de corredores quentes e frios é uma estratégia efetiva para gerenciar o fluxo de ar e melhorar a eficiência do resfriamento em data centers. Este conceito envolve a criação de corredores dedicados para o ar frio e quente, minimizando a mistura de ar e otimizando o uso de energia para resfriamento. A implementação correta dessa estratégia pode resultar em economias significativas de energia e melhorar a eficiência operacional do data center.
Alinhando a Direção do Fluxo de Ar com o Design do Data Center
A eficiência do resfriamento em data centers é fortemente influenciada pela direção do fluxo de ar dos equipamentos de TI. Ao integrar novos dispositivos, é essencial garantir que a direção do fluxo de ar esteja alinhada com o design do data center. Equipamentos que desviam do fluxo de ar padrão devem ser adaptados com mecanismos corretivos, como dutos ou gabinetes especiais, para assegurar que o ar seja direcionado de forma eficiente, mantendo a integridade do sistema de resfriamento.
Conclusão
A implementação de novos equipamentos de TI em data centers oferece uma oportunidade única para melhorar a eficiência energética e operacional. Adotando as práticas recomendadas e seguindo as diretrizes estabelecidas por organizações respeitadas, como ASHRAE, ISO/IEC e a União Europeia, os gestores de data centers podem garantir que seus equipamentos sejam não apenas poderosos e confiáveis, mas também sustentáveis e econômicos. A eficiência energética deve ser uma prioridade em todas as etapas do processo, desde a seleção de hardware até o design da infraestrutura e a implementação de estratégias de virtualização.
Referências
Para uma compreensão mais profunda das normas e padrões mencionados neste artigo, os leitores são encorajados a consultar diretamente as fontes, incluindo as diretrizes da ASHRAE, as normas ISO/IEC, a legislação da União Europeia, bem como as diretrizes específicas do Uptime Institute e The Green Grid para práticas de eficiência em data centers. Consulte também nosso artigo sobre o selo CEEDA de eficiência energética para data centers.
Este artigo é um convite para que profissionais da área de data centers reflitam sobre suas práticas atuais e busquem continuamente a inovação e a eficiência na gestão de seus equipamentos de TI, com o objetivo de alcançar a excelência operacional e a sustentabilidade ambiental.
O Certified Energy Efficient Datacenter Award (CEEDA) é um programa de certificação global, avaliado de forma independente, projetado para reconhecer a aplicação das melhores práticas de eficiência energética em data centers. Gerenciar um data center requer várias disciplinas especializadas, e o CEEDA foi criado para fornecer um processo de avaliação no qual os padrões dessas disciplinas são combinados para fornecer uma avaliação otimizada e holística das práticas de eficiência energética em condições do mundo real.
Estrutura do CEEDA
A estrutura do CEEDA é baseada em uma combinação de padrões, incluindo ASHRAE, Energy Star, ETSI, ISO, bem como o Código Europeu de Conduta e métricas Green Grid. Essa combinação fornece uma avaliação da eficiência energética e também das principais práticas de sustentabilidade com foco em energia, materiais, economia circular e o impacto de 8 dos 17 dos Objetivos de Desenvolvimento Sustentável da ONU.
Níveis de Certificação
A avaliação compreende uma estrutura graduada cumulativa desses critérios práticos. Para instalações em conformidade, a certificação resultante pode ser concedida nos níveis crescentes de Bronze, Prata e Ouro. A avaliação é um processo cumulativo – para ganhar Prata, o data center deve atender suficientemente ao nível Bronze. Para atingir o nível Gold, o data center deve atender suficientemente aos níveis Bronze e Silver.
Benefícios do CEEDA
O CEEDA oferece vários benefícios para as organizações. Ele permite que as organizações demonstrem publicamente sua liderança em Responsabilidade Social Corporativa (CSR). Além disso, o processo de avaliação auditada verifica de forma independente as principais métricas de desempenho, como Eficiência no Uso de Energia (PUE), métricas avançadas, como CUE/WUE, e o mix específico de energia do local. As instalações certificadas se beneficiam de um aumento médio de 5% a 15% na eficiência energética, bem como uma análise das lacunas operacionais em relação às melhores práticas mundialmente reconhecidas, proporcionando maior potencial para minimizar o impacto do carbono.
CEEDA no Brasil
No Brasil, a certificação CEEDA já está consolidada. Uma das empresas que conquistou a certificação no país foi a Embratel/Claro. Após receber, em 2016, a certificação “CEEDA in Progress” para o Data Center Lapa, a Embratel atingiu o nível Prata, após avaliação de um conjunto de critérios diferenciados, com base nas melhores práticas.
Por sua vez, a Dataprev, Empresa de Tecnologia e Informações da Previdência, investiu mais de R$ 200 milhões na modernização de seus Data Centers e buscou certificações para suportar e atender as necessidades das políticas públicas do Brasil. Em 2018, tornou-se a primeira empresa pública da América Latina a receber o selo CEEDA, que atesta as melhores práticas de eficiência energética de seus três Data Centers e confirma que a gestão e operação dos ambientes estão alinhadas com a estratégia de sustentabilidade operacional da empresa. Em resumo, o CEEDA é uma ferramenta valiosa para as organizações que buscam melhorar a eficiência energética de seus data centers. Ele fornece um quadro para avaliar o desempenho atual, identificar áreas de melhoria e demonstrar compromisso com a sustentabilidade. Para mais informações, visite o site oficial do CEEDA.
Em meu artigo anterior, mostrei a importância de uma boa gestão do fluxo de ar na refrigeração dos computadores de um data center. É uma boa ideia ler aquele artigo antes deste, pois lá explico os três principais problemas na gestão do fluxo de ar: ar frio desviado, recirculação do ar quente e pressão negativa. Neste artigo, vamos rever esses problemas e apresentar as soluções de confinamento de corredores, que complementam as práticas mostradas no artigo citado. Depois, leia meu artigo mais recente sobre o assunto.
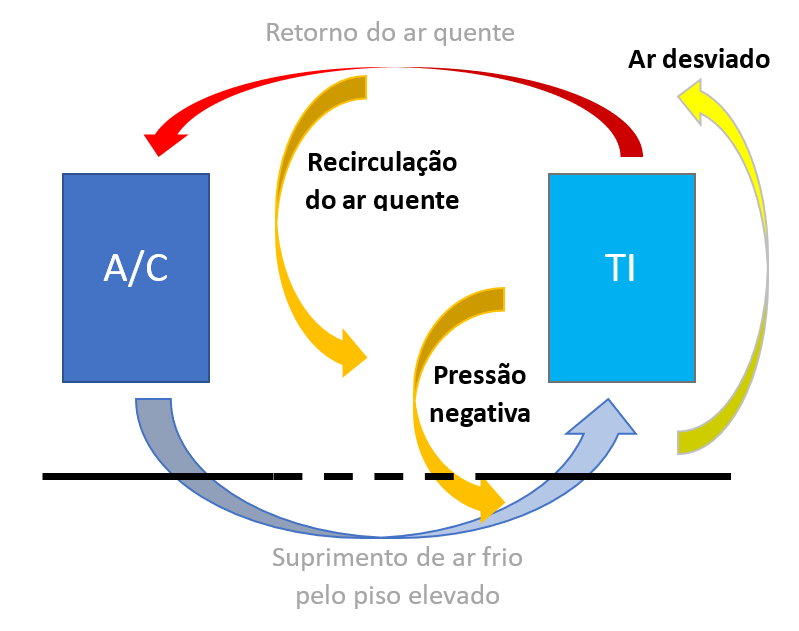
Vamos recordar esses principais problemas com a seguinte figura:
Problemas na gestão do fluxo de ar em data centers
É necessário evitarmos esses problemas com medidas tais como:
Fechar as posições de rack não utilizadas com tampas cegas
Não deixar espaços entre os racks da fileira
Selar as passagens de dutos e cabos que atravessam o pleno de fornecimento de ar frio (geralmente, o piso elevado)
Não colocar saídas de ar frio em locais que não sejam os corredores frios
Mesmo com todas essas medidas, ainda há locais por onde o ar frio ou o ar quente consegue escapar de seu corredor e acaba ocorrendo a mistura indesejada do ar quente com o frio: pelo topo e pelo final dos corredores, onde indicado pelas setas amarelas na figura abaixo.
É aí que entra a solução do “confinamento de corredores”, visando fechar esses dois locais (topo e final de corredores), evitando a mistura do ar quente com o frio. Podemos confinar o corredor quente ou o frio, usando anteparos sobre os racks e portas ao final dos corredores.
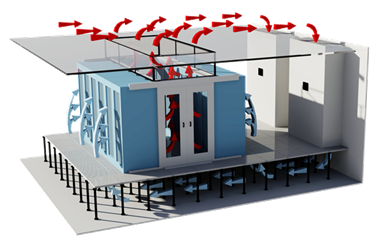
Confinamento do corredor frio
Ao confinar o corredor frio, evitamos que o ar resfriado fornecido pelo CRAC se desvie por qualquer outro lugar. A única maneira de ele retornar ao CRAC é passando através dos computadores instalados nos racks. É claro que precisamos fechar quaisquer outros potenciais “buracos” por onde o ar poderia sair.
Confinamento do corredor frio
Principais características dessa solução:
Menos volume de ar frio
O resto da sala é quente, o que poderia ser um problema para a instalação de equipamentos “stand alone” (fora de rack ou “de piso”), pois poderiam sobreaquecer
Maior uniformidade na temperatura do corredor frio
É mais fácil de ser aplicada quando os racks são padronizados
Cuidado para não pressurizar demais o corredor frio, senão o ar acaba se “desviando” por dentro dos computadores, ou seja, passa através deles mesmo não havendo muita necessidade.
Confinamento do corredor quente
Nesta solução, evitamos que o ar quente retorne aos computadores criando um “duto” entre o corredor quente e o retorno do CRAC. Esse retorno pode ser dutado ou através do plenum formado pelo forro. Na figura abaixo, o suprimento de ar frio não precisaria ser feito por sob o piso elevado, poderia também ser feito pelo ambiente.
Confinamento do corredor quente
Principais características dessa solução:
Maior volume de ar frio (o restante da sala)
O resto da sala é fria, permitindo a instalação de equipamentos “stand alone” sem problema de superaquecimento
O corredor quente fica muito quente, potencialmente levando a problemas de saúde ocupacional se alguém precisasse ficar muito tempo ali, pois esse corredor pode facilmente passar dos 40 °C
É mais fácil de ser aplicada quando os racks são padronizados
Rack chaminé
Esta é uma outra forma de confinamento do corredor quente, só que sem a criação do corredor quente em si. Cada rack confina seu próprio ar quente, possuindo portas traseiras seladas e uma chaminé que permite o retorno do ar quente ao CRAC através de dutos ou do plenum superior.
Rack chaminé
Principais características dessa solução:
Não tem corredor quente, evitando problemas de salubridade para quem precisar ficar atrás dos racks por muito tempo
O resto da sala é fria
Layout mais flexível, não necessitando a criação de corredores paralelos
Exige racks apropriados para tal solução, mas não precisam ser todos iguais
Conclusão
Existem diversas alternativas para a implementação do confinamento de corredores. Cada uma delas tem suas características, vantagens e desvantagens. De qualquer forma, implantar o confinamento é melhor do que não fazê-lo, qualquer que seja a solução adotada. Só não podemos descuidar dos demais pontos de atenção com relação à gestão do fluxo de ar, como detalhados no artigo citado no início deste.
Para saber mais, assista meu vídeo sobre confinamento de corredores:
Se achou este post útil, compartilhe, encaminhe a alguém que também possa achá-lo útil. Não deixe de se inscrever em meu canal do YouTube! Participe de meu grupo do Whatsapp e receba as novidades sobre meus artigos, vídeos e cursos. E curta minha página no Facebook!
Sobre o autor Marcelo Barboza, instrutor da área de cabeamento estruturado desde 2001, formado pelo Mackenzie, possui mais de 30 anos de experiência em TI, membro da BICSI e da comissão de estudos sobre cabeamento estruturado da ABNT/COBEI, certificado pela BICSI (RCDD e DCDC), Uptime Institute (ATS) e DCPro (Data Center Specialist – Design). Instrutor autorizado para cursos selecionados da DCProfessional, Fluke Networks, Panduit e Clarity Treinamentos. Assessor para o selo de eficiência para data centers – CEEDA.
Um data center é um ambiente de missão crítica bastante complexo, e que apresenta diversas particularidades. Neste artigo, trataremos sobre um problema bastante específico a esse tipo de ambiente: fluxo de ar para a refrigeração dos equipamentos de TI.
Todo equipamento de TI (como servidores, dispositivos de armazenamento e de comunicação), que tratarei neste artigo simplesmente por “computador”, precisa ser refrigerado, pois durante sua operação ele esquenta. Se não removermos o excesso de calor, o computador pode falhar ou desligar automaticamente, causando prejuízos aos serviços prestados pelo data center.
Para a refrigeração dos computadores, os data centers contam com máquinas de ar-condicionado de diferentes tecnologias e capacidades. Não vamos entrar em detalhes, aqui, sobre as máquinas de ar-condicionado (CRAC – Computer Room Air Conditioner). Vamos, sim, explorar alguns problemas que acontecem entre o ar-condicionado e os computadores. Pois há um fluxo de ar entre esses dois tipos de máquinas: o ar frio fornecido pelo CRAC e que deve ser captado pelo computador; e o ar aquecido pelo computador, que deve retornar ao CRAC para ser resfriado novamente.
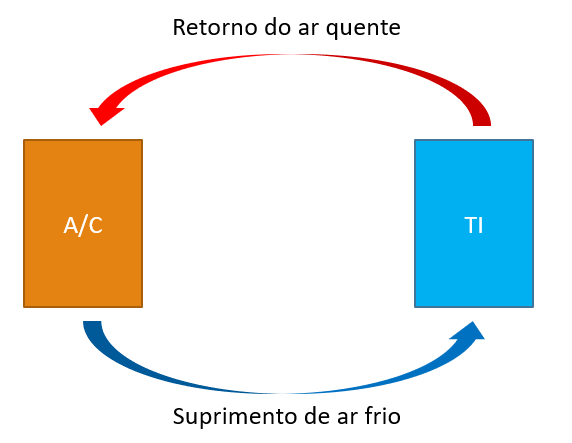
Idealmente, é um ciclo fechado, como podemos ver na figura abaixo:
Mas o mundo real está longe da perfeição, e há alguns problemas que afetam esse fluxo, afetando, consequentemente, a eficiência do sistema de refrigeração e, por conseguinte, aumentando seu custo, já que levará a um aumento no consumo de energia por parte dos CRACs.
Podemos dividir esses em três diferentes tipos:
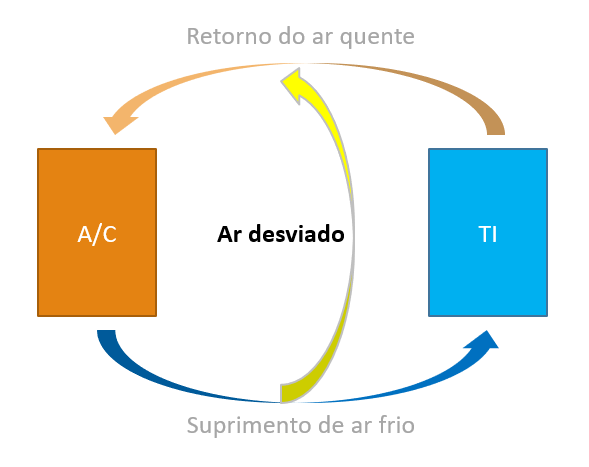
Ar frio desviado
Recirculação do ar quente
Pressão negativa
Ar frio desviado
Neste caso, nem todo o ar resfriado pelo CRAC chega até os computadores. Parte dele se desvia de seu destino e acaba se misturando com o ar quente que retorna ao CRAC, como podemos ver no diagrama abaixo:
Quando isso acontece, menos ar resfriado chega aos computadores, além de diminuir a temperatura do ar que retorna ao CRAC. Uma das consequências é o aumento da temperatura dos computadores, já que não chega ar suficiente para resfriá-los. Para compensar isto, precisamos aumentar a potência das ventoinhas do CRAC, aumentando também seu consumo elétrico.
Outra consequência é a diminuição da temperatura do ar de retorno ao CARC. Como o ar desviado se mistura a esse retorno, sua temperatura acaba ficando inferior àquela do ar que sai dos computadores. Isso diminui a eficiência do CRAC e “engana” o sistema, pois, como o ar chega mais frio, “achamos” que está tudo bem quando, na verdade, poderia até estar ocorrendo algum “hot spot” no data center e nem ficamos sabendo!
O ar frio é desviado quando o fornecemos em locais onde os computadores não poderão captá-lo. Por exemplo, quando colocamos placas de piso perfuradas em locais que não o “corredor frio”, quando deixamos abertos os furos de passagem de cabos atrás dos racks, ou quando o piso elevado não está bem alinhado. Também pode ocorrer quando o ar frio escapa por cima ou pelas laterais do corredor frio sem ser captado pelos computadores.
Piso desalinhado
Furo para passagem de cabos por onde o ar é desviado
Solução para fechamento do furo para passagem de cabos
Este vídeo explica com mais detalhes o ar desviado:
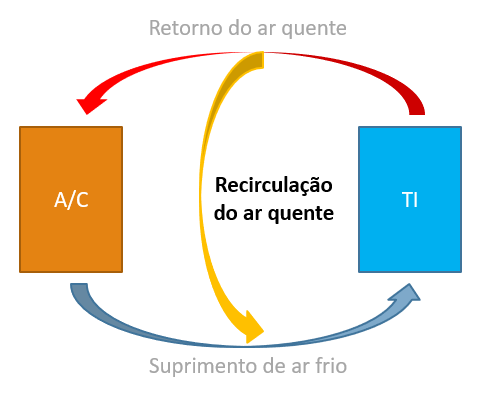
Recirculação do ar quente
Idealmente, todo o ar quente que sai dos computadores deveria retornar ao CRAC. Mas isso nem sempre acontece, e parte dele acaba recirculando pelo próprio computador, entrando novamente por sua captação de ar frio. Consequentemente, a temperatura do ar que entra pelo computador acaba aumentando, o que pode provocar sobreaquecimento, levando a desligamento, diminuição de vida útil e falhas. Isso nos obriga a aumentar a potência de resfriamento do CRAC, aumentando também seu consumo elétrico.
Esse ar quente pode retornar para os próprios computadores por dentro, por cima ou pelas laterais dos racks. Para evitar isso, deve haver uma separação total entre o lado de trás do rack (corredor quente) e o lado da frente (corredor frio). E deve-se atentar para não instalar no rack equipamentos que tenham seu fluxo de ar divergente desse padrão.
Uma boa ideia é sempre instalar placas cegas nas posições não usadas dos racks, e não deixar aberturas entre eles.
Exemplo de tampa cega entre posições ocupadas
Aqui e aqui você pode comprar online tampas cegas para seu rack para evitar a recirculação do ar quente.
Este vídeo explica com mais detalhes a recirculação do ar quente:
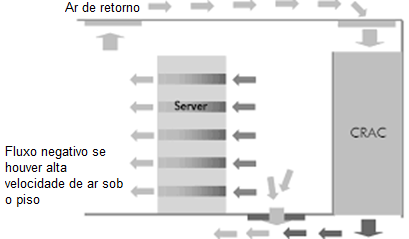
Pressão negativa
Abaixo do piso elevado, nas proximidades do CRAC downflow, o ar por ele fornecido ainda está com muita velocidade. E ar em velocidade possui menos pressão que ar parado. E, como sabemos, o ar flui de onde tem mais pressão para onde tem menos. Se colocarmos uma placa de piso perfurada muito perto (a menos de 1,8 m) do CRAC, o ar do ambiente será sugado para baixo do piso, pois ali haverá uma “pressão negativa” (menos pressão abaixo do piso do que acima).
Ao ser sugado, o ar ambiente (mais quente) “contaminará” o ar recém resfriado fornecido pelo CRAC, aumentando sua temperatura. Os efeitos serão semelhantes aos do ar quente recirculado: aumento da temperatura do ar fornecido aos computadores. Para compensar, precisamos “esfriar” ainda mais a sala, gastando mais energia.
O ideal é nunca posicionar as placas de piso perfuradas muito perto dos CRACs. Converse com o projetista do sistema de climatização para ver a distância mínima recomendada.
Este vídeo explica um pouco mais sobre a pressão negativa:
Conclusão
Refrigerar o data center e manter a temperatura dos computadores na faixa ideal é muito mais do que simplesmente ter os CRACs corretamente dimensionados, instalados e operacionais. O fluxo de ar é parte integrante do sistema de climatização do data center, e há muitos detalhes que devem ser observados para que os objetivos do sistema sejam alcançados.
Se achou este post útil, compartilhe, encaminhe a alguém que também possa achá-lo útil. Não deixe de se inscrever em meu canal do YouTube! Participe de meu grupo do Whatsapp e receba as novidades sobre meus artigos, vídeos e cursos. E curta minha página no Facebook!
Sobre o autor Marcelo Barboza, instrutor da área de cabeamento estruturado desde 2001, formado pelo Mackenzie, possui mais de 30 anos de experiência em TI, membro da BICSI e da comissão de estudos sobre cabeamento estruturado da ABNT/COBEI, certificado pela BICSI (RCDD e DCDC), Uptime Institute (ATS) e DCPro (Data Center Specialist – Design). Instrutor autorizado para cursos selecionados da DCProfessional, Fluke Networks, Panduit e Clarity Treinamentos. Assessor para o selo de eficiência para data centers – CEEDA.
Este meu vídeo também explica os conceito básicos da
medição do PUE:
Conceitos básicos do PUE
Como vimos, o PUE mostra o overhead de energia gasto em relação aos sistemas de TI. Esse overhead representa a energia gasta nos sistemas que auxiliam na contínua operação dos sistemas críticos de TI, incluindo, mas não necessariamente se limitando a:
Energia gasta na refrigeração/ventilação dos equipamentos de TI e dos equipamentos necessários ao seu funcionamento, incluindo bombas, chillers, ventoinhas, torres de resfriamento, fancoils, evaporadoras e condensadoras
Perdas elétricas nos equipamentos, cabos e conexões da distribuição elétrica (ex.: UPS, quadros elétricos, transformadores, geradores etc.)
Alimentação elétrica de sistemas auxiliares necessários, como alarmes de incêndio, controle de acesso e automação
Iluminação das salas que compõem o data center
Ao computar a energia gasta pelos sistemas de TI, deve-se considerar, para além de servidores, armazenamento e comunicações (switches e roteadores), todo o equipamento de TI suplementar, como monitores, chaveadores KVM, estações de monitoramento etc., desde que necessários à operação dos serviços críticos.
Então, um data center com PUE 1,60 significa que 60% de toda a energia por ele consumida é gasta por esses sistemas acima listados como overhead. Obviamente, quanto mais perto de 1,00, mais eficiente esses sistemas serão ao atenderem as necessidades de TI.
Mas, onde medir o consumo de TI e qual a unidade utilizada? A primeira edição do PUE descrevia somente uma relação entre picos de demanda. Ou seja, durante um período de avaliação (por exemplo, durante um mês), é anotado o pico de demanda total do data center (DEM_TOT) e o pico de demanda dos equipamentos de TI (DEM_TI), ambos medidos em kW. O PUE seria então DEM_TOT/DEM_TI. Exemplo: pico de demanda do data center durante um ano = 500 kW, pico de demanda de TI durante esse ano = 300 kW; PUE = 500/300 = 1,67.
Posteriormente, foi lançada a segunda versão do PUE, em três níveis, 1, 2 e 3. Esse novo PUE (versão 2) prefere que o cálculo seja feito com dados de consumo, em kWh, e não de demanda, como anteriormente. Então, durante o período de avaliação, é medido o consumo elétrico total do data center (CONS_TOT) e o dos equipamentos de TI (CONS_TI). O PUE é agora CONS_TOT/CONS_TI. Exemplo: consumo elétrico total do data center durante um ano = 4.500.000 kWh, consumo elétrico de TI durante esse ano = 2.600.000 kWh; PUE = 4.500.000/2.600.000 = 1,73. Esta maneira é superior à anterior, pois utiliza o consumo total, que já contabiliza todos os picos, vales e sazonalidades ocorridas durante o período.
Os três níveis do PUE versão 2 se referem ao local onde deve ser medido o consumo de TI, bem como periodicidade mínima da medição (se usada a demanda pontual):
PUE1: nível 1; medição na saída do UPS; se medido como demanda (kW), a periodicidade deve ser mensal ou semanal
PUE2: nível 2; medição na saída do PDU; se medido como demanda (kW), a periodicidade deve ser diária ou horária
PUE3: nível 3; medição na tomada elétrica dos equipamentos de TI (nos racks); se medido como demanda (kW), a periodicidade deve ser de 15 minutos ou menos
Atualmente, o PUE também é definido na norma ISO/IEC 30134-2 – Power usage effectiveness (PUE).
A medição do consumo total deve ser sempre realizada na entrada do data center. Deve-se deduzir daí toda energia utilizada para outros sistemas não relacionados ao data center, se existirem.
Quanto mais perto da carga de TI for a medição, ou seja, quanto maior o nível do PUE, mais precisa será a métrica ao identificar as perdas decorrentes do overhead das instalações.
Quando a medição for realizada por consumo (kWh), é importante manter o cálculo do PUE trimestral de cada estação climática do ano, bem como o anual, de forma a ressaltar (trimestral) e a nivelar (anual) os efeitos da temperatura externa no PUE.
O PUE1 e o PUE2 até admitem ter suas medições de consumo realizadas de forma manual, em rondas periódicas. É relativamente fácil obter dados de consumo de TI para o PUE1, pois todos os UPS já vêm com recursos para informar os dados de fornecimento de energia. Para o PUE2, é necessária a instalação de medidores nos quadros principais de distribuição de energia ininterrupta para o data center (PDU).
O PUE3, por sua granularidade (medição em cada rack de TI), deve necessariamente ser medido de forma automática. Isso não deve ser um problema, pois para o PUE3 é necessária a utilização de “PDU inteligente de rack” em todos os racks, os quais já são naturalmente dotados de capacidade remota de monitoramento, via SNMP ou equivalente. Porém, isso torna a instalação mais cara, portanto não é uma solução viável para muitos data centers.
Se o data center adquirir outros recursos utilizados para alimentação elétrica ou refrigeração, como diesel ou gás (para geração local regular), ou água potável (para refrigeração), a energia embutida em tais insumos também deve ser contabilizada na energia total consumida pelo data center. A norma do PUE inclui fatores para a conversão dessa energia embutida em energia a ser contabilizada pelo PUE.
O PUE, em princípio, não deve ser utilizado para comparar instalações diferentes, a não ser que a metodologia de todos os locais seja compatibilizada. O PUE é bastante útil para servir de base para o próprio data center medir sua evolução com o tempo e após alterações significativas da instalação.
Mas, atenção, o PUE não mede a eficiência elétrica dos equipamentos de TI! O aumento da eficiência de TI (com o uso de técnicas de consolidação e virtualização, por exemplo) reduzirá o consumo elétrico do data center, mas, se não houver um correspondente ajuste no parque eletromecânico, o PUE poderá aumentar, mesmo que o consumo total da instalação tenha diminuído.
Por outro lado, aumentar muito a temperatura de fornecimento do ar condicionado, para a faixa “permitida” da ASHRAE, poderá proporcionar uma boa economia no gasto energético da refrigeração. Mas, dependendo da temperatura e nível de carga dos servidores, pode ser que suas ventoinhas sejam aceleradas ao máximo, para compensar esse aumento. Isso pode levar a um consumo extra que anula os ganhos com a redução da refrigeração, levando a um maior consumo do data center. Nesse caso, paradoxalmente, o PUE pode melhorar, pois o consumo das ventoinhas dos servidores é contabilizado como consumo de TI!
Ou seja, o PUE não deve ser o único recurso para acompanhar a eficiência elétrica do data center. Ele deve sempre ser acompanhado por outros indicadores, como o consumo elétrico total e índices de eficiência dos equipamentos de TI, como por exemplo o ITEU e o ITEE, também definidos na norma ISO/IEC 30134.
Seguem os links para os sites onde se pode adquirir os documentos aqui citados:
A medição do PUE é apenas um dos itens avaliados para a obtenção do único selo de eficiência energética para data centers, o CEEDA. Mais informações, aqui: http://www.ceedacert.com/
O cálculo do PUE é abordado nos cursos DCDA e EnergyPro, do DCProfessional. Mais informações, aqui: https://www.br.dcpro.training/
Se achou este post útil, compartilhe, encaminhe a alguém que também possa achá-lo útil. Não deixe de se inscrever em meu canal do YouTube! Participe de meu grupo do Whatsapp e receba as novidades sobre meus artigos, vídeos e cursos. E curta minha página no Facebook!
Sobre o autor Marcelo Barboza, instrutor da área de cabeamento estruturado desde 2001, formado pelo Mackenzie, possui mais de 30 anos de experiência em TI, membro de comissões de estudos sobre cabeamento estruturado e data center da ABNT, certificado pela BICSI (RCDD, DCDC), Uptime Institute (ATS) e DCPro (Data Center Specialist – Design). Instrutor autorizado para cursos selecionados da DCProfessional, Fluke Networks, Panduit e Clarity Treinamentos. Assessor para o selo de eficiência para data centers – CEEDA.
Como já vimos em outros artigos, disponibilidade é algo primordial para os data centers atuais, tendo sido criadas até classificações, conhecidas como tiers.
Mas hoje em dia há outra característica a ser valorizada, que é a eficiência energética do data center, que é a sua capacidade de operar com menor consumo de energia. Energia elétrica é um recurso caro, portanto desperdiçá-lo não é uma boa ideia. E para podermos reduzir seu consumo precisamos, antes de mais nada, saber medi-lo e, em seguida, utilizar métricas que possam nos informar com que grau de sucesso estamos atingindo nossos objetivos de melhoria da eficiência.
O assunto eficiência energética em data centers começou a preocupar em 2008, a partir de um relatório ao Congresso dos EUA, quando verificaram que os data centers norte-americanos seriam responsáveis pelo consumo de aproximadamente 1,5% de toda a energia elétrica produzida no país! A última estatística, de 2014, aponta para um aumento para 2%.
Mas, antes de falarmos sobre alguma métrica de eficiência, vamos analisar quais os principais sistemas consumidores de energia elétrica de um data center. Obviamente, o principal tipo de equipamento existente em um data center, e que precisa ser energizado, é o equipamento de TI, motivo último da existência do data center. Nessa categoria estão os servidores, os dispositivos de armazenamento (storage) e os equipamentos de comunicação (como switches e routers). Todos os demais equipamentos e dispositivos que consomem energia em um data center são auxiliares ao funcionamento dos sistemas de TI. Dentre os principais sistemas auxiliares, podemos citar os seguintes: geração alternativa de energia (geradores), energia ininterrupta (UPS ou no-breaks), climatização, segurança patrimonial e incêndio, iluminação, monitoramento e automação. Vamos denominá-los conjuntamente de “sistemas de infraestrutura”.
Resumindo, temos dois grandes sistemas consumidores de energia elétrica no data center: os sistema de TI e os sistemas de infraestrutura. Ambos somados correspondem ao consumo do data center como um todo. A proporção entre ambos e entre os diferentes sistemas componentes pode variar bastante a cada data center.
Neste artigo vamos abordar apenas a métrica que mede a proporção de consumo elétrico entre os sistemas de infraestrutura e o de TI, chamada de PUE – Power Utilization Effectiveness, ou efetividade da utilização da energia, criada pelo The Green Grid. Ela indica o quanto de tudo o que consumimos no data center é relativo aos sistemas de infraestrutura. E por quê isso é importante? Se pensarmos bem, os únicos sistemas que deveriam necessariamente consumir algo são os de TI. São eles que importam. Qualquer gasto com sistemas de infraestrutura deveria ser visto como um overhead, um gasto extra, embora inevitável. Se queremos um ambiente estável, controlado e seguro para os sistemas de TI, é natural que gastemos alguma energia extra com isso. A questão é: quanto de energia estou gastando para manter esse ambiente, para além daquilo que é estritamente consumido pelos equipamentos de computação, armazenamento e comunicação?
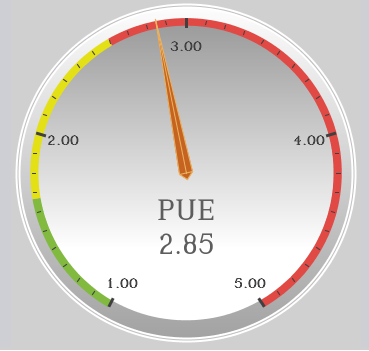
Se analisarmos uma certa quantidade de data centers, veremos que é comum que metade de todo o consumo elétrico seja devido aos sistemas de infraestrutura, ou seja, PUE de 2.0, pois o cálculo do PUE é simplesmente a divisão do consumo energético total do data center pelo consumo dos sistemas de TI, para um determinado período. Exemplo: o data center todo consome 4 GWh em um ano, sendo 2 GWh em TI e 2 GWh em sistemas de infraestrutura, portanto PUE = 4 / 2 = 2.0. Embora um PUE de 2.0 seja relativamente comum, esse valor é alto. Veja a interpretação de valores de PUE:
PUE 3.0: muito ineficiente
PUE 2.5: ineficiente
PUE 2.0: médio
PUE 1.5: eficiente
PUE 1.2: muito eficiente
Note que não foi colocado o valor PUE = 1.0, pois em tese nunca teremos um data center que direcione 100% da energia elétrica para os sistemas de TI. Sempre haverá algum consumo devido à infraestrutura, nem que sejam apenas as perdas da distribuição elétrica. Mas, quanto mais o valor do PUE se aproximar da unidade, mais eficiente será os seus sistemas de infraestrutura, ou seja, menos energia eles consumirão em relação àquilo que é consumido por TI.
Um dos sistemas de infraestrutura que mais consome energia no data center é a climatização. Para um data center onde TI consome metade de toda a energia (PUE = 2.0), é normal que os sistemas de climatização consumam por volta de 40% do total, os demais 10% ficando principalmente com as perdas elétricas e demais sistemas auxiliares. É bastante usual, portanto, que as tentativas de redução do PUE se deem principalmente pela melhoria da eficiência do sistema de climatização do data center.
Em data centers profissionais, que utilizam o estado da arte em eficiência energética, podemos ver valores de PUE iguais ou inferiores a 1.1! Para se ter uma ideia, a média de PUE de todos os data centers do Google, medida em período de 12 meses, é de apenas 1.12. Veja aqui. Em termos práticos, PUE de 1.12 significa que a cada 1000 Wh consumidos pelos sistemas de TI, apenas 120 Wh são consumidos pelos sistemas de infraestrutura, incluindo a climatização e as perdas elétricas!
Se você analisar alguns gráficos de PUE medidos ao longo do tempo, verá que ele variará em ciclos. Isso se deve à variação de eficiência do sistema de climatização, que é altamente dependente das condições climáticas do ambiente externo ao data center. Dias mais quentes exigem mais dos sistemas de ar condicionado, piorando o PUE momentaneamente. Data centers que possuem PUE muito baixo somente são possíveis em locais onde o clima local é ameno ou é possível a utilização de recursos naturais (como ar ou água) naturalmente frios (free cooling), reduzindo o consumo dos sistemas de climatização.
É importante termos a consciência de que o PUE não é a única métrica a ser utilizada para medir a eficiência energética do data center. Como vimos, ele mede o overhead de energia gasto em relação aos sistemas de TI. Mas, e o gasto dos sistemas de TI em si? Será que não poderíamos ter os mesmos serviços de TI, mas com um consumo energético menor? Menos energia consumida por TI levaria a menor necessidade de gastos com os correspondentes sistemas de infraestrutura que o suportam. Existem técnicas de melhoria de eficiência energética para cada sistema de infraestrutura de um data center. Estas técnicas, mais as técnicas de redução de consumo de TI, farão parte de um futuro artigo para este blog.
Existem, porém, algumas dificuldades para o cálculo do PUE. Como dito no início, a primeira etapa é a correta medição do consumo de TI e dos sistemas de infraestrutura. E aí já surgem as questões:
Onde devo medir o consumo de TI? Em algum quadro elétrico? Na saída de algum equipamento de distribuição elétrica? Na entrada do equipamento de TI? Tanto faz?
Quais gastos devem entrar na medição do consumo da energia total consumida pelo data center?
Se o data center compartilha um edifício com áreas de escritório ou produção, como medir corretamente o consumo do data center?
Se a central de água gelada fornece água para todos os sistemas de ar condicionado do edifício, incluindo o data center, como ratear isso?
Eu meço demanda ou consumo? Pico ou média?
Como definir os períodos de medição?
Conceitos básicos do PUE
Como vemos, embora o cálculo do PUE em si seja simples, ele suscita diversas dúvidas, que devem ser endereçadas com precisão antes de implantarmos tal métrica em nosso data center. Voltaremos ao assunto PUE em futuros artigos para este blog.
Se achou este post útil, compartilhe, encaminhe a alguém que também possa achá-lo útil. Não deixe de se inscrever em meu canal do YouTube! Participe de meu grupo do Whatsapp e receba as novidades sobre meus artigos, vídeos e cursos. E curta minha página no Facebook!
Sobre o autor Marcelo Barboza, instrutor da área de cabeamento estruturado desde 2001, formado pelo Mackenzie, possui mais de 30 anos de experiência em TI, membro de comissões de estudos sobre cabeamento estruturado e data center da ABNT, certificado pela BICSI (RCDD, DCDC), Uptime Institute (ATS) e DCPro (Data Center Specialist – Design). Instrutor autorizado para cursos selecionados da DCProfessional, Fluke Networks, Panduit e Clarity Treinamentos. Assessor para o selo de eficiência para data centers – CEEDA.
Antes de mais nada, vamos definir “downtime”: é o tempo em que os serviços providos pelo data center ficam interrompidos. Podemos interromper seus serviços, basicamente, de duas formas: por paradas planejadas ou por paradas não planejadas. Paradas planejadas são usualmente realizadas durantes serviços de atualização ou manutenção de equipamentos, componentes, hardware ou software. Mas neste artigo vamos nos ater às paradas não planejadas, que são as mais temidas, pois, justamente por não serem planejadas, são as que causam mais impacto e, portanto, ocasionam mais prejuízos à empresa. Aqui, então, downtime será sinônimo de parada não planejada.
Qual será a principal causa de downtime, então? Segundo estudo publicado em 2016 pelo Ponemon Institute, “Cost of Data Center Outages”, a principal causa raiz de downtime, de acordo com os três estudos já realizados por eles (2010, 2013 e 2016), tem sido: falha em UPS! Ou seja, falha no sistema que deveria justamente manter fornecimento elétrico aos serviços de TI de maneira contínua, ininterrupta e com qualidade! Um quarto (25%) de todas as paradas tem sido causadas por esse motivo, de acordo com esse estudo, que contou com a participação de 63 data centers norte-americanos.
E qual o segundo lugar? Pasmem, a segunda colocação ficou com o crime cibernético, com 22%! Um aumento de 11 vezes desde o primeiro estudo, de 2010, quando ele representava apenas 2% das causas de downtime. Foi a causa que apresentou o maior crescimento dentre as sete principais causas identificadas no estudo (UPS, cybercrime, erro humano, climatização, clima, gerador, equipamento de TI). Empatado com o cybercrime, temos o erro humano, também com 22% das causas.
E em último lugar dentre as causas identificadas, temos as falhas em equipamentos de TI, com apenas 4% das causas de downtime. Mas aí que vem a surpresa: embora os equipamentos de TI representem apenas 4% das causas de falhas, eles são responsáveis pelos maiores prejuízos quando falham! Em média, o downtime causado por falhas em equipamentos de TI provoca prejuízos na ordem de US$ 995.000, seguido de perto pelo cybercrime (US$ 981.000), contra US$ 709.000 quando a causa é o UPS. O erro humano causa perdas médias na ordem de US$ 489.000.
Qual será o custo por minuto de um data center parado de forma não planejada? Os número variam bastante, desde US$ 926 até US$ 17.244 por minuto! Neste quesito, os números apresentam constante crescimento. O custo médio de downtime aumentou 38% entre 2010 e 2016, enquanto o custo máximo reportado aumentou 81% no mesmo período!
Finalmente, os três segmentos de mercado que apresentam os maiores custos por decorrência de downtime são, em ordem decrescente: Serviços Financeiros, Comunicações e Saúde.
Como podemos diminuir todo esse downtime? Existem diversas técnicas, que passam pela implantação de níveis de redundância, escolha de componentes de melhor qualidade, melhor localização do data center, treinamento do pessoal de operação, cumprimento de rigoroso plano de manutenção preventiva e preditiva, criação de uma documentação abrangente e precisa da instalação e dos processos, para citar os principais. Para saber um pouco mais sobre as classificações em níveis de redundância, leia este artigo de nosso blog ou veja este vídeo:
A classificação de um data center em tiers
A correta operação do data center é crucial para manter sua disponibilidade. Para saber mais sobre o assunto, veja essa entrevista que conduzi ao vivo com dois profissionais extremamente experientes nessa área:
Você, que de alguma forma está envolvido no mundo dos data centers, com certeza já ouviu falar da classificação “tier” de data centers. Mas, sabe realmente o que ela significa?
Primeiramente, “tier” é uma palavra inglesa que significa nível ou camada. Sua pronúncia pode ser conferida aqui. Neste artigo, usaremos a palavra “nível” no lugar de tier.
No ecossistema dos data centers, a classificação em níveis se refere ao grau de redundância que seus sistemas de infraestrutura possuem. O objetivo da redundância é prover maior disponibilidade aos serviços de TI fornecidos pelo data center. Apenas lembrando, redundância não é o único recurso para aumento da disponibilidade; itens como qualidade dos componentes e equipamentos, treinamento do pessoal de operação e localização do data center também são cruciais para esse objetivo. A classificação tradicional em níveis não engloba esses itens.
Perguntas inevitáveis: como definir esses graus de redundância? Quais sistemas entram na avaliação? E é aí que as coisas complicam, pois existem diversas normas e padrões que definem níveis de redundância, e cada uma responde a essas questões de maneira diferente. Somente para citar as mais conhecidas, tanto o padrão “Tier Standard: Topology”, do Uptime Institute, quanto as normas TIA-942 e BICSI-002, ambas publicadas pela ANSI, definem níveis de redundância, nem sempre compatíveis entre si (consulte meu artigo sobre Normas Para Data Centers). Até os nomes diferem, cada qual utiliza um diferente: tier, level e class. Além disso, a BICSI-002 define cinco classes de redundância, enquanto as duas outras definem apenas quatro.
Os sistemas que entram na classificação também nem sempre são os mesmos. Enquanto os níveis do Uptime Institute focam apenas nos sistemas elétricos e mecânicos, os dois outros englobam os sistemas de cabeamento, segurança, arquitetura, dentre outros. E os requisitos para cada nível também não são exatamente os mesmos. Neste artigo, portanto, vamos procurar definir quatro níveis de redundância com o que há de consenso entre esses padrões e normas. Não entraremos em detalhes de cada nível, já que cada norma ou padrão detalha esses níveis de maneira um pouco diferente.
Nível 1/Tier I: este nível na verdade não estabelece nenhum tipo de redundância da infraestrutura. Ele apenas estabelece os requisitos básicos que devem ser cumpridos, em termos de provisionamento de infraestrutura, para termos um data center minimamente disponível. Por exemplo, é necessário que geradores de backup e seus tanques e bombas de combustível, UPS (no-break) e sistemas completos de climatização, os chamados “componentes de capacidade”, existam e estejam corretamente dimensionados para toda a carga crítica de TI prevista para o data center. Um data center nível 1 é capaz de prover alguma disponibilidade dos sistemas de TI, já que possui energia ininterrupta e de backup, além de um clima adequado aos equipamentos, mas não pode manter os serviços durante manutenções preventivas ou corretivas. Adequado, portanto, para pequenas instalações, que não sejam tão críticas ao negócio da empresa.
Nível 2/Tier II: aqui já é especificada uma redundância mínima dos componentes de capacidade, de forma a aumentar a disponibilidade dos serviços de TI. Manutenções preventivas de alguns equipamentos de infraestrutura (como UPS, p.ex.) podem ser realizadas sem prejuízo à disponibilidade. Algumas falhas em equipamentos redundantes também podem não comprometer os serviços críticos, mas não dá para garantir isso, já que geralmente as especificações de nível 2 não pedem para haver redundância nos “caminhos de distribuição” (p.ex., cabos alimentadores elétricos, tubulações de água gelada e backbones ópticos); manutenção ou falha em algum desses caminhos provoca indisponibilidade nos serviços. Dependendo do tipo de manutenção preventiva, também é possível que os serviços precisem ser interrompidos. O nível 2 é adequado para instalações pequenas ou médias onde a criticidade do negócio é maior, não suportando muito bem indisponibilidades durante o horário comercial.
Nível 3/Tier III: um data center nível 3 tem que possuir redundância suficiente para que qualquer (veja bem, eu disse QUALQUER!) manutenção preventiva possa ser realizada na infraestrutura sem que haja a necessidade de se suspender nenhum serviço crítico de TI. Isso é o que chamamos de “manutenção simultânea”. Para tanto, não pode haver nenhum ponto único de falha, requerendo redundância também nos caminhos de distribuição, sendo que a qualquer momento apenas um dos caminhos deve ser necessário para suportar a carga crítica. Para ser efetivo, é preciso que todo equipamento de TI possua fontes redundantes de energia, conectadas a caminhos elétricos diversos. Durante manutenções preventivas, parte dos componentes de capacidade devem ser desligados, e os sistemas críticos de TI devem ser atendidos pelos componentes redundantes. Nesse momento, ele fica mais sujeito a paradas imprevistas, pois a redundância é temporariamente “perdida”. Algumas falhas em componentes de capacidade podem ser cobertas pelos componentes redundantes, mas dependendo da falha, ou se houver mais de uma falha simultânea, o sistema poderá cair. Este é o nível mínimo para empresas que funcionam 24×7, sem possibilidade de paradas nos serviços de TI para manutenção da infraestrutura.
Nível 4/Tier IV: como vimos, alguns tipos de falha podem tirar um data center nível 3 do ar, como por exemplo um incêndio em uma sala de geradores. Como o nível 4 trata essa possibilidade? Requerendo que, fora da sala de computadores, todos os equipamentos de capacidade redundantes sejam instalados em salas separadas, em zonas de incêndio diferentes. Todo caminho de distribuição redundante externo à sala de computadores também deve manter essa separação. E para os sistemas redundantes entrarem em ação, não podem depender de ações humanas, isso tem que ser automático! Portanto, a ideia é que o nível 4 seja tolerante a falhas. Nenhuma falha isolada, em nenhum dos componentes de capacidade (equipamento ou caminho), pode resultar em indisponibilidade do sistemas críticos. Mesmo um incêndio em uma sala elétrica, já que os sistemas redundantes estarão em outra sala, isolada da primeira. Um exemplo de incidente que pode parar um data center nível 4 é um incêndio na sala de computadores. É um nível indicado para o data center principal de empresas que não podem sobreviver sem os serviços por ele disponibilizados, a todo o tempo.
A classificação dos data centers em tiers
A forma de implementar cada um desses níveis, quais sistemas são afetados, e o detalhamento das prescrições e recomendações, como já dito, dependem de qual norma ou padrão é utilizado. Algumas entidades possuem programas de certificação, sendo qualificadas a auditar o projeto ou as instalações e, posteriormente, emitir selos de conformidade a algum dos níveis pertinentes.
Mais alguns detalhes importantes sobre níveis de redundância de data centers:
Embora não mencionadas aqui, existem outras entidades que possuem métodos de classificação em níveis, como por exemplo o ICREA
Essa classificação se aplica a cada data center de maneira isolada, ou seja, dois data centers fisicamente distantes, mas “espelhados” em tempo real, não configuram um nível 3 ou nível 4, cada um deve ser classificado independentemente do outro
Os níveis constantes nos padrões aqui expostos não se aplicam aos sistemas de TI em si, apenas aos componentes da infraestrutura, comumente chamados de “facilities”; ou seja, executar sistemas de TI em diferentes servidores do data center, como forma de redundância, não afeta a classificação em níveis e nem é afetado por ela
Se achou este post útil, compartilhe, encaminhe a alguém que também possa achá-lo útil. Não deixe de se inscrever em meu canal do YouTube! Participe de meu grupo do Whatsapp e receba as novidades sobre meus artigos, vídeos e cursos. E curta minha página no Facebook!
Sobre o autor Marcelo Barboza, instrutor da área de cabeamento estruturado desde 2001, formado pelo Mackenzie, possui mais de 30 anos de experiência em TI, membro de comissões de estudos sobre cabeamento estruturado e data center da ABNT, certificado pela BICSI (RCDD, DCDC), Uptime Institute (ATS) e DCPro (Data Center Specialist – Design). Instrutor autorizado para cursos selecionados da DCProfessional, Fluke Networks, Panduit e Clarity Treinamentos. Assessor para o selo de eficiência para data centers – CEEDA.